Winning the NCVPRIPG23 Challenge on Writer Verification
The Challenge
The statement is simple. Given two images of handwritten texts, predict whether they’ve been written by the same person or not. This challenge was a part of the 8th National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics. You can go and have a look at the above link for the details of the challenge and dataset (as of writing the dataset isn’t public).

You can also have a look at the project repository along with this blog.
- Used a
ResNet50withDINOpretrained weights. - Trained the network using triplet loss.
- Final test AUC is 0.97588 in just 10 epochs.
Exploratory Data Analysis (EDA)
For exploring computer vision datasets I use Voxel51, which is one of the coolest tools to qualitatively view your dataset. You can go ahead and read their extensively detailed documentation along with tutorials to get an idea of the power it has. Using it for this challenge was as simple as doing
pip install fiftyone
import fiftyone as fo
def fiftyone_vis(dataset_dir: str):
# Create the dataset
dataset = fo.Dataset.from_dir(
dataset_dir=dataset_dir,
dataset_type=fo.types.ImageClassificationDirectoryTree,
name=name,
)
session = fo.launch_app(dataset)
session.wait()The above code is generic enough to view any dataset organized in the standard :ImageFolder structure of PyTorch. The session.wait() is important to keep the server running. Here is the amazing visualization which we get:
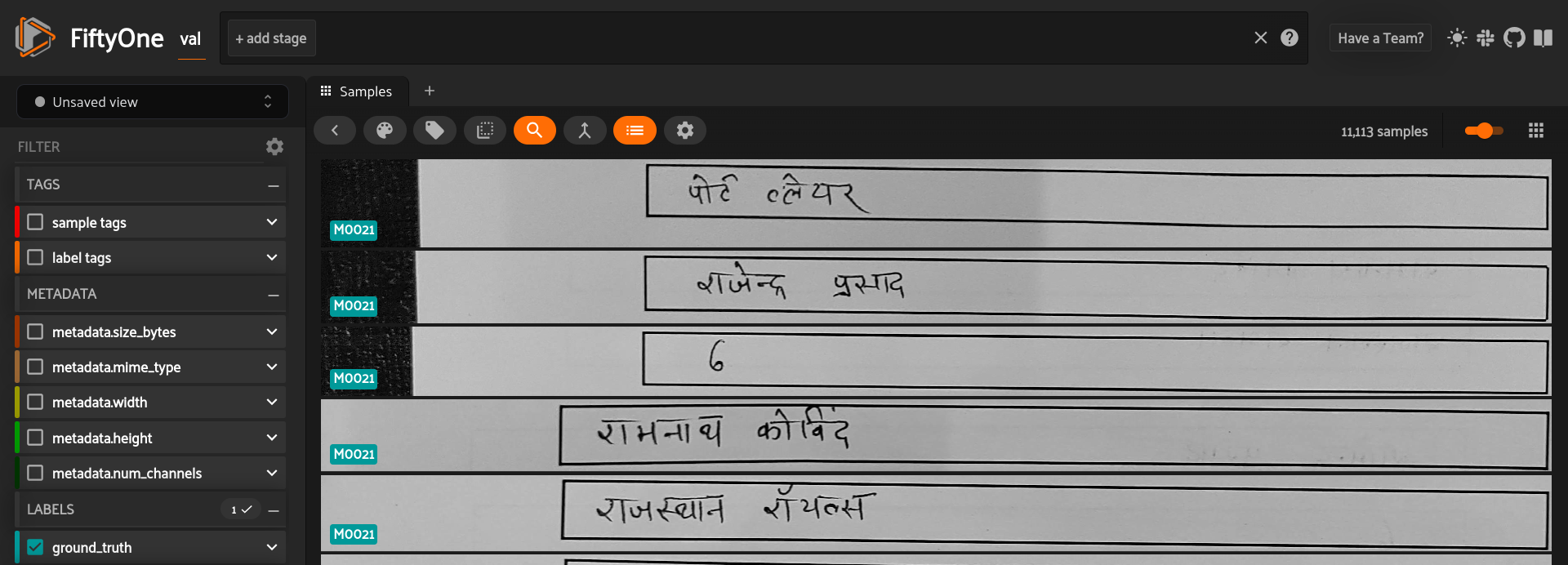
We can clearly see the class labels and several other filters/tools in the dashboard. The images are of varying sizes and with only a few images per writer class. The written text contains English alphabets, special symbols (punctuations, superscript, digits, special chars), lines, paragraphs, 2 text boxes in one image, printed text, strikes, written text going outside the black boundary box, text written at angles and a few blank texts.
Although there is a lot of scope for preprocessing, I started without it to find out the initial results, which turned out to be pretty decent.
Model Architecture
Due to a large number of writer classes and only a few images per class, the problem can be modelled into a metric learning task, where the goal is to learn a similarity function between pairs of images. With this similarity metric, we would finally be able to predict whether two texts come from the same writer (by setting an appropriate threshold).
The overall architecture consists of two things
- The encoder part (backbone) to encode images.
- The loss function to train the model on.
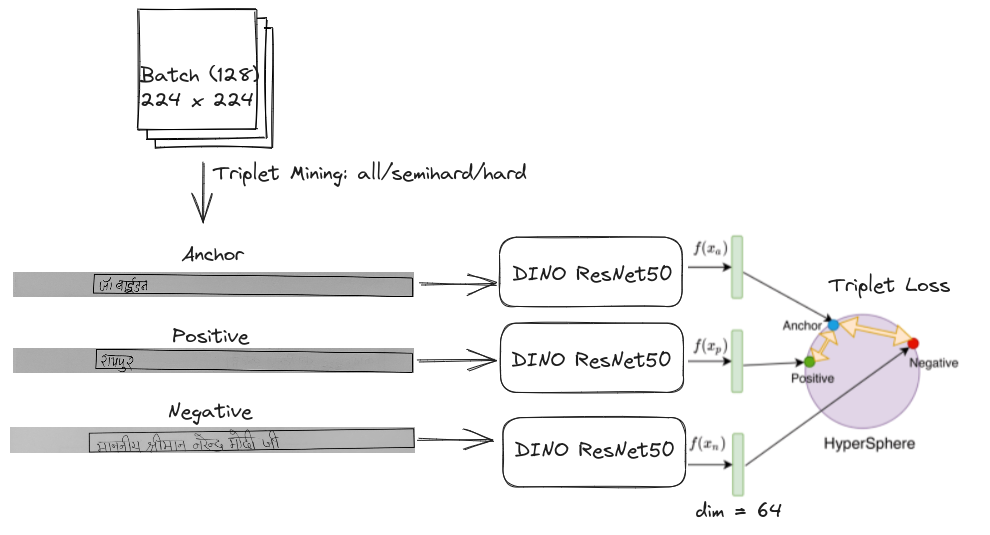
The Image Encoder
The encoder is a simple ResNet50 with an output dimension of 64 (instead of the default 1000). For getting a good backbone, I thought of using DINO pretrained weights on ImageNet. Several papers have shown this backbone to be strong in downstream metric learning tasks. I just started with a ResNet50, but a ViT could’ve been tried too, along with the more recent DINOv2 weights. I used a generic classifier from the Transfer Learning Library, which can be configured to have different backbones, bottlenecks and heads. Another benefit is that the learning rates of different layers can also be configured.
The Triplet Loss
The triplet loss seemed to be one of the ideal choices to train the network on. The motivation comes from the following:
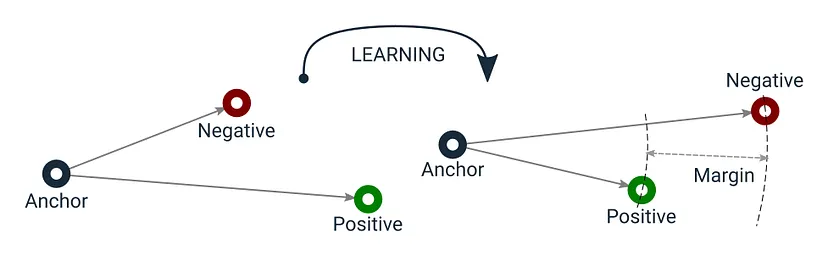
The loss is defined by,
$$ L(a,p,n) = max\{d(a_i, p_i)-d(a_i, n_i) + margin, 0\} $$
Where,
$a - \textnormal{denotes the anchor}$
$p - \textnormal{denotes the positive (image from the same writer class as anchor)}$
$n - \textnormal{denotes the negative (image from a different writer class as anchor)}$
$d - \textnormal{distance metric (CosineSimilarty in this case)}$
$\textnormal{margin }-\textnormal{ distance between (ap) and (an) pairs}$
Triplets are mined by a $\verb|TripletMarginMiner|$ function depending on specific conditions. I kept the margin as 0.2 (could’ve been a hyperparameter) in all experiments.
Training
A learning rate of 0.01 was used for the head (fc layer), 0.001 was used for the backbone, along with adam as the optimizer and an exponentially decaying $lr$ scheduler.
The $lr$ decays every epoch according to,
$$lr = lr_0(1 + 0.001lr)^{-0.75}$$
The choice of hyperparameters in this case is purely based on some past experience with using the Transfer-Learning-Library.
RandomSampler for sampling images of a batch, I made use of an :MPerClassSampler from the pytorch-metric-learning library, which samples $M=4$ images of every class in a batch. The benefit of doing this is a much faster convergence due to the production of a large number of triplets in a batch, making it more useful than random sampling.
Results and Conclusions
Here is an overview of some of the ablations that were conducted.
| AUC (Val) | Batch Size | Miner | Sampler | Epochs |
|---|---|---|---|---|
| 0.7217 | 32 | semihard | - | 20 |
| 0.9642 | 128 | semihard | - | 80 |
| 0.9782 | 128 | all | - | 80 |
| 0.9775 | 128 | all | MPerClass | 10 |
- It is clear from the table that one needs a larger batch size (which is obvious in metric learning tasks).
allmining strategy generates more triplets, and this strategy works slightly better than the other options.hardmining resulted in the loss to collapse and ultimately halt training, due to a decrease in the triplets mined after a few epochs.- An
MPerClassSamplergreatly improves training time. - The AUC of the best model on the
valset turned out to be 0.9775 and that of the test set turned out to be 0.97588
Overall, it was an amazing experience for me to win my first challenge.